S’il fallait schématiser l’e-réputation, quatre aspects essentiels, quatre angles ou prismes d’analyse, apparaitraient : l’aspect documentaire,
celui des « systèmes », celui cognitif, et enfin le prisme managérial. Voyons ce que supposent ces quatre approches et ce qu’elles peuvent apporter à une organisation en termes
d’analyse et de construction.
S’il fallait schématiser l’e-réputation, quatre aspects essentiels, quatre angles ou prismes d’analyse, apparaitraient : l’aspect documentaire,
celui des « systèmes », celui cognitif, et enfin le prisme managérial. Voyons ce que supposent ces quatre approches et ce qu’elles peuvent apporter à une organisation en termes
d’analyse et de construction.
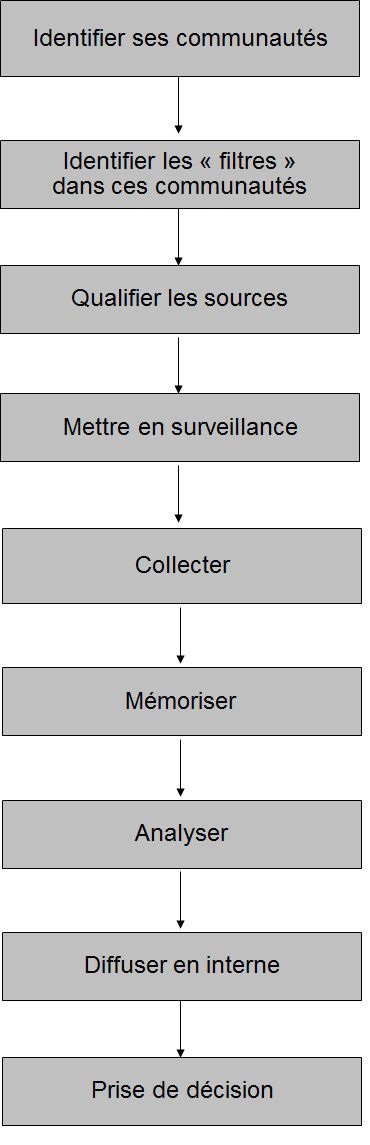
Avec le développement grandissant des usages du web, des spécificités des plates-formes, des outils et méthodes d’analyse, mais aussi des attentes des organisations en matière de stratégies numériques (et d’e-réputation), l’analyse de l’e-réputation mérite d’être considérée plus largement qu’un simple comptage de likes et de commentaires, ou une mesure de visibilité SEO.
Ce qui est proposé ici est très schématique mais permet de regrouper en quatre grands aspects/pôles/prismes/angles d’analyse l’e-réputation d’une organisation. Cela suppose donc que l’e-réputation se construit principalement (mais pas que, bien entendu) par ces 4 aspects. Cette aproche offre à une organisation (ou un veilleur/manager) la possibilité de mieux organiser ou segmenter son processus d’analyse. Voire de répartir les tâches entre différents métiers ou collaborateurs présents dans l’organisation, tant ces aspects supposent parfois des compétences bien différenciées.
La figure ci-dessous représente ces angles d’attaque, ces aspects constitutifs de l’e-réputation d’une organisation, et ils sont détaillés ensuite. Ainsi que les différentes combinaisons possibles entre eux.

Aborder l’e-réputation par son aspect documentaire
L’analyse de l’e-réputation se concentre sur l’expression des opinions des internautes : notes, avis, commentaires, critiques… Sur le web, exprimer son opinion revient à produire un document : tweet, billet de blog, photos, vidéos…
L’aspect documentaire de l’e-réputation et l’analyse qu’il suppose est alors essentiel pour mieux appréhender cette réputation en ligne, et par la suite la construire, la développer ou la gérer. Ce prisme d’analyse de l’e-réputation englobe alors plusieurs « sous-aspects », plusieurs phénomènes à analyser :
==> La question du support. C’est-à-dire le document en lui-même, la manière dont il s’organise, et dont il est techniquement construit. Mais aussi tout ce qui vient enrichir ce support, à savoir les différentes métadonnées ajoutées par les internautes, les traces d’interactions voire les données personnelles qui le constituent
==> La question des marqueurs documentaires. Les RTs, Likes, étoiles sur Ebay, notes, scores Klout, etc., sont un ensemble de marqueurs documentaires qui ont une signification et qu’il convient d’aborder comme tels. Ils viennent donner du sens aux documents en eux-mêmes, sont des indicateurs de l’opinion exprimée, permettent de redéfinir le contexte ou le sens donné à une opinion…
==> La question du remix (ou redocumentarisation). Lorsqu’une image (par exemple) est remise dans un contexte différent que celui d’origine (comme d’un blog à un autre), lorsque certains ajouts y sont faits (cf. mème et lolcats), l’interprétation possible de cette image devient différente. Et qui dit de multiples interprétations, dit un impact différent sur l’opinion et in fine l’e-réputation de ce qui est représenté par cette image. Comprendre ces mécanismes documentaires (qu’ils soient endogènes- par l’internaute, ou automatisés) est essentiel pour analyser l’e-réputation d’une organisation.
==> L’identité numérique. Considérant que « l’homme est un document comme les autres », l’analyse de l’identité numérique des internautes s’inscrit dans ce cadre documentaire. Auu-delà d’une analyse des traces d’usage ou des données personnelles, l’identité numérique suppose un passage de l’influence à l’autorité réputationnelle, une nouvelle manière de hiérarchiser les informations sur le web qui est alors nécessaire d’appréhender pour mieux analyser son e-réputation…
Aborder l’e-réputation par les systèmes
Autrement dit, questionner les algorithmes qui gouvernent les plates-formes, qui plus est quand ceux-ci fonctionnent en boite noire. Et cela pour pouvoir par la suite analyser :
==> La visibilité. Celle des contenus, des sources, des documents, voire des internautes. Cette analyse, des centaines de critères de Google par exemple, est inhérente à l’e-réputation et aux questions de « qu’est-ce que les internautes voient, ou pas ».
==> La mémorisation : mais qu’est-ce que telle ou telle plate-forme conserve, comment, pourquoi ?...
==> Le traitement automatisé, qui englobe les questionnements précédents. Approche dans lequel est inclue celle des traces, autrement dit de ce que les systèmes conservent et de la manière dont ils les traitent par la suite (personnalisation des contenus ou de la navigation, recommandation, publicité, etc.).
Le développement des outils de traitement et d‘analyse de grand jeux de données, l’ouverture (partielle) de API des plates-formes et l’engouement pour les « big data » permettent alors d’obtenir certaines réponses à ces questionnements. Bref, d’aborder l’internaute par le prisme des systèmes afin de mieux définir et analyser l’e-réputation de l’organisation.
Aborder l’e-réputation par son aspect cognitif
C’est-à-dire sur le traitement effectué…par le cerveau des internautes. Car si la réputation repose sur des interprétations, qu’elle suppose la formulation d’opinions ou de sentiments, alors il convient de s’intéresser au traitement interne effectué par un sujet. Et cela afin de questionner :
==> L’attention. Celle portée à tel ou tel contenu par exemple. Avec les questions sous-jacentes d’ergonomie et d’architecture des supports (en s’appuyant sur des techniques d’eye tracking par exemple), de surcharge cognitive ou informationnelle, etc.
==> L’opinion. Si l’opinion suppose en partie une formulation par le groupe, et que par définition une opinion est toujours formulée (contrairement à un jugement), il n’en reste pas moins que celle-ci repose sur des expériences internes à un individu qu’il convient de questionner (ou tout du moins de prendre en compte : une opinion ne reflète pas « tout ce que pense un individu à propos de »)…
==> Les sentiments. Graal de pas mal d’éditeurs d’outils, les sentiments sont un ressenti qui est unique pour chaque individu, et qui ne peut être exprimé tel qu’il est ressenti. Autrement dit, ce n’est pas parce que je dis « ce truc me fait peur » que pour autant on pourra mesurer ou mettre sur une échelle cette « peur ». Bref, une analyse quasi inaccessible de l’extérieur…
Pour cette approche, une question reste en suspens : mais comment faire ? D’ici à ce que l’on puisse mettre des flux RSS dans le cerveau ou que, plus sérieusement, le neuromarketing se développe nettement (mais les questions d’éthique trouvent encore trop peu de réponses pour souhaiter ce développement), seul des extrapolations, le recours à des approches qualitatives/déclaratives classiques (entretiens, etc.) et une analyse fine du contexte (comme pour les sentiments) peuvent apporter des billes à l’analyse.
Aborder l’e-réputation par son aspect managérial
Soit, ce que l’e-réputation offre à une organisation en termes de prise de décision, en lui permettant notamment : de s’auto-évaluer par l’analyse du contexte informationnel numérique dans lequel elle évolue, de s’orienter au sein des communautés voulues, de définir des discours en adéquation avec ces communautés, de définir les actions de gestion à développer… En somme, de ne plus voir l’e-réputation comme la simple constatation de « ce qui se dit sur l’organisation », mais plutôt comme un outil décisionnel, une manière de définir et d’influer sur l’environnement pertinent d’une organisation.
L’aspect managérial suppose aussi de se questionner sur le fonctionnement interne de l’organisation, sur les process ou collaborateurs centraux ou à risques, sur la manière dont les médias sociaux sont utilisés par ces collaborateurs, sur le fonctionnement du SAV, les procédures qualités… Bref, tout ce qui en interne participe à la construction de cette e-réputation.
L’e-réputation et son analyse comme une combinaison de ces aspects
De nombreux aspects propres à l’e-réputation ou à son analyse semblent manquer dans cette approche très schématique. Ils peuvent être cependant mis en avant par le croisement des différents aspects présentés précédemment :
==> Aspect documentaire + aspect systèmes = questions liées au référencement naturel plus spécifiquement, à l’optimisation des contenus, au rédactionnel, ou encore à la mesure quantitative de « l’influence »
==> Aspect documentaire + aspect cognitif = analyse de la socialisation de l’internaute (les commentaires qu’il fait, la manière dont il lie ses profils avec d’autres, etc.) ainsi que de la formulation des opinions (analyse sémantique, lexicale, en contexte)
==> Aspect documentaire + aspect managérial = analyse de l’autorité des sources d’information, mais aussi des actions de community management entendues ici comme la production et la diffusion de documents en ligne (tweets, updates Facebook, etc.)
==> Aspect systèmes + aspect cognitif = analyse de l’influence sociale (qualitative), des questions de recommandation de l’information, de surcharge cognitive…
==> Aspect systèmes + aspect managérial = questions liées au marketing virale, au « nettoyage », et globalement tout ce qui concerne la diffusion et la mise en visibilité de contenus
==> Aspect cognitif + aspect managérial = analyse des sentiments, et community management (entendu dans le sens « créer et avoir de l’empathie pour sa marque et avec son public », voire « devenir une référence dans tel ou tel domaine »).
Au final…
Si cette approche en 4 blocs ou 4 facettes de l’e-réputation est très schématique, elle permet néanmoins de définir ce qui construit l’e-réputation d’une organisation, et de coordonner ou organiser son analyse. Cela permet aussi d’expliquer simplement en quoi consiste (par exemple) une veille en e-réputation, mais aussi les actions à prévoir pour construire ou gérer l’e-réputation (plus agir sur tel aspect que sur tel autre, etc.).
Bien entendu, il manque à ce billet les techniques/méthodes pour mettre en place ces analyses (certaines sont cependant déjà présentes
sur ce blog), mais cela ne devrait pas tarder à arriver ![]()
Et pour vous, quels sont les aspects inhérents à l’e-réputation ? Quels sont vos prismes d’analyse ?!



 La question du signal faible, ou « signe d’alerte précoce », est inhérente à la veille (qui se veut anticipative par nature) mais aussi par extension à
l’e-réputation : peut-on identifier à l’avance une possible crise ou une information critique ? Cette question est toujours ouverte à l’heure actuelle, et les réponses qui lui sont
données restent généralement techniques (l’outil magique). Petit retour sur cette problématique.
La question du signal faible, ou « signe d’alerte précoce », est inhérente à la veille (qui se veut anticipative par nature) mais aussi par extension à
l’e-réputation : peut-on identifier à l’avance une possible crise ou une information critique ? Cette question est toujours ouverte à l’heure actuelle, et les réponses qui lui sont
données restent généralement techniques (l’outil magique). Petit retour sur cette problématique.
 Un certains « darwinisme 2.0 » voudrait que chaque organisation gère son e-réputation… Au-delà du fait que toute organisation est
différente, et n’a donc pas les mêmes besoins, il apparait aussi des raisons amenant à dire que, non, il n’y a pas nécessité ou alors il ne vaudrait mieux pas se lancer dans une stratégie de
gestion de l’e-réputation.
Un certains « darwinisme 2.0 » voudrait que chaque organisation gère son e-réputation… Au-delà du fait que toute organisation est
différente, et n’a donc pas les mêmes besoins, il apparait aussi des raisons amenant à dire que, non, il n’y a pas nécessité ou alors il ne vaudrait mieux pas se lancer dans une stratégie de
gestion de l’e-réputation. Après être passée par des prestataires, une organisation peut questionner son besoin d’internaliser la gestion de sa réputation en ligne
(notamment
Après être passée par des prestataires, une organisation peut questionner son besoin d’internaliser la gestion de sa réputation en ligne
(notamment 


 Twitter a supprimé l’accès direct à ses flux RSS. Seulement, pour les veilleurs, difficile d’automatiser un tant soit peu sa veille sans RSS. Voici donc 10 astuces, très simples, pour
récupérer rapidement des flux sur Twitter : ceux de votre timeline, de votre compte, des recherches ou encore des listes.
Twitter a supprimé l’accès direct à ses flux RSS. Seulement, pour les veilleurs, difficile d’automatiser un tant soit peu sa veille sans RSS. Voici donc 10 astuces, très simples, pour
récupérer rapidement des flux sur Twitter : ceux de votre timeline, de votre compte, des recherches ou encore des listes.